The MirageOS Blog
on building functional operating systems
MirageOS Security Advisory 03 - infinite loop in console output on xen
- Module: solo5
- Announced: 2022-12-07
- Credits: Krzysztof Burghardt, Pierre Alain, Thomas Leonard, Hannes Mehnert
- Affects: solo5 >= 0.6.6 & < 0.7.5, qubes-mirage-firewall >= 0.8.0 & < 0.8.4
- Corrected: 2022-12-07: solo5 0.7.5, 2022-12-07: qubes-mirage-firewall 0.8.4
- CVE: CVE-2022-46770
For general information regarding MirageOS Security Advisories, please visit https://mirageos.org/security.
Background
MirageOS is a library operating system using cooperative multitasking, which can be executed as a guest of the Xen hypervisor. Output on the console is performed via the Xen console protocol.
Problem Description
Since MirageOS moved from PV mode to PVH, and thus replacing Mini-OS with solo5, there was an issue in the solo5 code which failed to properly account the already written bytes on the console. This only occurs if the output to be performed does not fit in a single output buffer (2048 bytes on Xen).
The code in question set the number of bytes written to the last written count (written = output_some(buf)), instead of increasing the written count (written += output_some(buf)).
Impact
Console output may lead to an infinite loop, endlessly printing data onto the console.
A prominent unikernel is the Qubes MirageOS firewall, which prints some input packets onto the console. This can lead to a remote denial of service vulnerability, since any client could send a malformed and sufficiently big network packet.
Workaround
No workaround is available.
Solution
The solution is to fix the console output code in solo5, as done in https://github.com/Solo5/solo5/pull/538/commits/099be86f0a17a619fcadbb970bb9e511d28d3cd8
For the qubes-mirage-firewall, update to a solo5 release (0.7.5) which has the issue fixed. This has been done in the release 0.8.4 of qubes-mirage-firewall.
The recommended way to upgrade is:
opam update
opam upgrade solo5
Correction details
The following PRs were part of the fix:
- solo5/pull/538 - xen console: update the "to be written" count
- qubes-mirage-firewall/pull/167 - update opam repository commit
Timeline
- 2022-12-04: initial report by Krzysztof Burghardt https://github.com/mirage/qubes-mirage-firewall/issues/166
- 2022-12-04: investigation by Hannes Mehnert and Pierre Alain
- 2022-12-05: initial fix by Pierre Alain https://github.com/Solo5/solo5/pull/538
- 2022-12-05: review of fix by Thomas Leonard
- 2022-12-07: release of fixed packages and security advisory
References
You can find the latest version of this advisory online at https://mirageos.org/blog/MSA03.
This advisory is signed using OpenPGP, you can verify the signature
by downloading our public key from a keyserver (gpg --recv-key 4A732D757C0EDA74),
downloading the raw markdown source of this advisory from
GitHub
and executing gpg --verify 03.txt.asc.
After 2.5 years of silent period due to Covid 19, we re-started the MirageOS retreats in early October 2022. This time 15 people gathered in Mirleft (southern Morocco) since it is directly at the sea side, less crowded and stressful than Marrakesh. We had a very nice venue with excellent food and a swimming pool. The group was diverse with the majority from Western Europe, but also attendees from the USA and Nigeria. Some participated for the first time, while others were regular participants. This is great, because it creates a good atmosphere with a shared knowledge of organization, i.e. that we have a daily circle, we do our own dishes, the network setup is run by MirageOS unikernels.
The journey to Mirleft is slightly longer than to Marrakesh, a large group met a day earlier in Agadir and shared a 2.5 hours Taxi ride 130km south. Another group met in the afternoon in Agadir and did the same trip. There is as well public transport by bus every other day to Marrakesh, which some people took on the way back.
The great food and local organization was done again by our hosts who are usually in Marrakesh, but who were happy to host us in Mirleft. Big thanks to the Queens collective.

We plan to have again more regular retreats in the future, they will be announced on the MirageOS developer mailing list, and likely on the discussion forum, and on the retreat website.
Network setup
Once again we used a 4G modem as uplink. One gigabyte of data was 10 Dirham (roughly one Euro), which we collected when the data volume was close to being exceeded. The 4G connectivity was much better than in Marrakesh, likely due to less congestion on the countryside. An APU (tiny x86 computer from PC Engines APU with a serial connection) running FreeBSD was at the heart of our network: the 4G modem was connected via USB, and some TP link access points for wireless connectivity. The routing and network address translation (NAT), which allowed all the laptops and mobile phones to connect to the Internet via the 4G modem was done by the FreeBSD host system (due to lack of a unikernel just doing this, something to prepare for the next event).
For network address configuration and domain name resolution we used DNS Vizor, a MirageOS unikernel on the FreeBSD system with solo5 hvt. We also deployed two other MirageOS unikernels: a local bob relay for sharing files, and used a local opam mirror to reduce our bandwidth use.
While the retreat developed, the DNS resolution was not very stable since the resolver on the 4G modem was sometimes overloaded by lots of requests via a single TCP connection. In the first days we developed UDP support for the MirageOS dns-client and the local connectivity experience greatly improved.
Day to day activities
Apart from talking to old and new friends face-to-face, which we haven't done for some time, we also worked on various projects to improve the MirageOS ecosystem. Below is a collection of projects that wouldn't come to existance without the retreat. Please excuse if there's some project missing.
In the day time we discussed various topics, including performance considerations and how to write protocol implementations with GADTs. Next to that people were going to the beach, while others were pairing up for some projects or reading code together. Others worked alone on finishing some code, but whenever a question of another library appeared, it was easy to approach the original author or someone who has used that library extensively and discuss some questions. In the evenings we had some impromptu talks about various topics, such as the opam repository CI, Lwt do's and dont's, BGP, monitoring, Raspberry pi PWM.
One afternoon we did a long dragon dreaming session to figure out the ideas and dreams for the future of MirageOS. Apart from bare-metal and MirageOS as hypervisor, we also dreamed about running your own digital infrastructure with MirageOS (with increased decentralization and security). Another afternoon we had a cocktail party at the pool.
Some participants already wrote articles about their journey and activities, take a look at their writings: Raphaël Proust, Jules, Sayo, Enguerrand, Sonja, Jan, Lucas, Pierre.
OCaml 5 support
OCaml 5 will soon be published, which has most of the runtime code being rewritten. The runtime also has many more dependencies. We worked on getting ocaml-solo5 (the piece consisting of a math library, a C library, and the OCaml compiler for MirageOS unikernels) to use OCaml 5. This is still work in progress, but already lead to some upstream PRs that are merged into the 5 branch as well.
A Verified File System for MirageOS
FSCQ is a formally verified file system developed in the Coq proof assistant. So far MirageOS has a variety of read/write file systems: chamelon (LittleFS) tar (append-only), fat (FAT16 with its limitations), and one file FS (supporting only one file). We wanted to add FSCQ to the list, by making it usable from MirageOS (currently it compiles to Haskell code).
At the retreat, we first repaired some FSCQ proofs to work with recent Coq releases, and then added OCaml wrapper code and revised the OCaml extraction. The current state is that the most obvious bugs have been fixed, the filesystem is usable from FUSE and underwent basic testing, but performance needs to be improved. FSCQ was developed with lazyness in mind targeting Haskell; for instance, it uses lots of lists in a way that does not go well with OCaml's strict evaluation. The progress is tracked in this issue.
Uint128
A long-standing issue in our IP address library is to use a different memory presentation for IPv6 addresses. As foundation we developed a uintb128 package.
Qubes firewall
Originally developed in 2016, over the last months we revived the QubesOS (an OS that executes applications each in a separate virtual machine for improved security) MirageOS firewall and removed mutable state and improved performance. Read more in Pierre's article.
Music bare-metal on Raspberry Pi 4
Based on gilbraltar (which now works with newer gcc versions), a jack port driver was developed. With this program we now listen to music with MirageOS all day and night. Read further in Tarides blog We also made some music and recorded an EP, read further in Tarides blog.
HTTP client for MirageOS
The earlier mentioned opam mirror contained a HTTP client (using HTTP/AF and H2, supporting both HTTP1 and HTTP2 and also IPv4 and IPv6) to download archives - and we had similar code in other projects. That's why we decided to create the http-mirage-client opam package to reuse that code.
DNS resolver with filtering advertisement
This package is already picked up and used by Mirage Hole, a DNS stub resolver that filters advertisement domains (based on a domain lists downloaded via HTTP using the above HTTP client), which was developed from scratch in Mirleft. Read further in Tarides blog.
Albatross meets NixOS
Albatross is an orchestration system for MirageOS unikernels using solo5 (spt or hvt). Apart from console output, statistics, and resource policies, it supports remote management using TLS. Now albatross supports NixOS and there is a tutorial how to set it up. Read further in Tarides blog.
Memory leaks
We chased some memory leaks on this website, using Grafana and mirage-monitoring. This lead to a PR in paf. We are still investigating another memory issue. Read further details in Tarides blog.
Opam cache
Apart from the opam mirror, sometimes only the caching part is very useful, especially since the git interaction is quite expensive for the network and CPU. We developed a cache-only version in a branch.
Fixing the DNS resolver in the mirage tool
The default DNS resolver in MirageOS is uncensoreddns, which discontinued plaintext DNS requests and replies, and instead supports DNS-over-TLS. We fixed our code to delay parsing of nameservers and update the mirage tool. Now, with the release 4.3.1, name resolution with conduit's resolver works fine again.
Caqti and pgx
We conducted some work on integrating the pure OCaml PostgreSQL client pgx with caqti.
Lwt
Quite some discussion was for how to use exceptions in lwt, leading to a proposed PR not to capture out of memory and stack overflow exceptions, and export reraise. Read further in Raphaël's blog.
Tarides Map
A map showing the geographic distribution of Tarides collaborators was developed as a unikernel, see the code. Read further in Tarides blog article.
Slack bot
The coffee chat bot earlier worked as an executable on Unix, now it can be executed as a MirageOS unikernel. Read further in Tarides blog article.
At Robur, we have created many unikernels and services over the years using MirageOS, like OpenVPN, CalDAV, a Let’s Encrypt solver using DNS, DNS Resolver, authoritative DNS servers storing in a Git remote, and other reproducible binaries for deployment. We chose OCaml because of its advanced security, compiler speed, and automated memory management. Read more about how Robur benefits from OCaml and MirageOS on our website.
Most recently, we worked on producing and deploying binary unikernels, funded by the European Union under the NGI Pointer programme.
OpenVPN
Robur started the development of OpenVPN, a virtual private network protocol, in OCaml in 2019. The original C implementation served as documentation of the protocol. We developed it in OCaml using existing libraries (cryptographic operations, networking, NAT) and parsers (for the configuration file angstrom, for the binary packets cstruct). We re-use the same configuration file format as the C implementation (but do not yet support all extensions), so the MirageOS unikernels can be used as drop-in replacements. OCaml improved the project by enhancing security and minimising our codebase.
We created OpenVPN as a MirageOS unikernel to forward all traffic to a single IP address or local network NAT through the OpenVPN tunnel. To increase security even further, we designed a fail-safe that dropped all packets (rather than sending them unencrypted) when the OpenVPN tunnel was down.
This project was funded by Prototype Fund in 2019. The code is available on GitHub.
CalDAV
Robur started the CalDAV project back in 2017 with a grant from the Prototype Fund, which came with the stipulation that it had to be created within six months! Thus the first version of CalDAV emerged from those efforts. Afterward, Tarides sponsored Robur so we could continue CalDAV’s development and draft an inital CardDAV implementation, resulting in the version now available.
As you might’ve guessed from the name, CalDAV is a protocol to synchronise calendars, and it works on a robust server that’s relatively easy to configure and maintain. This enables more people to run our own digital infrastructure rather than rely on an outside source. Robur’s CalDAV provides considerable security, due to its minimal codebase, and stores its data on Git for version control. We even set up a live test server at calendar.robur.coop that contains the CalDavZAP user interface, accessible with any username and password.
CalDAV also comes with some client control with its ability to be tracked and reverted, so you can remove entries from undesirable behavior. Plus, it can be exported and converted to/from other formats!
Robur’s tests of the basic tasks for maintaining a digital calendar, like adding or modifying an event, have all successfully passed with several different CalDAV clients, but we hope to develop CalDAV further by adding notifications on updates via email and integrating an address book. If you’re interested in donating or investing in CalDAV, please contact us through our website.
The code for CalDAV is also released to opam-repository; the code for CardDAV is not yet integrated nor released.
DNS Projects
Robur engineers have created robust DNS Projects, like our ‘Let’s Encrypt’-Certified DNS Solver, a DNS Resolver, and an authoritative DNS Server. As a refresher, users navigate the Internet using domain names (addresses in cyberspace), and DNS stands for Domain Name System. These systems take the domain name (something easy to remember, like robur.coop), and reroute them to the IP address (not easily remembered, like 193.30.40.138). The term IP address is short for Internet Protocol address, and its numbers point to a specific server, city, state/region, postal code, etc. In other words, it’s the actual machine’s address. These IP addresses take users to the website's files, and they’re what enable you to send and receive emails, too. DNS stores all these key values (with caching) in a decentralised hierarchy, making it fault-tolerant to minimise problems.
Robur’s authoritative DNS server delegates responsibility for a specific domain and provides mapping information for it, ensuring that the user gets to the correct IP address. At the other end of the process, Robur’s DNS resolver finds the exact server to handle the user’s request. To keep the codebase minimal for security and simplicity, we included only the elements absolutely necessary. The 'Let's Encrypt' unikernel waits for certificate requests in the zones (encoded as TLSA records), and uses a 'Let's Encrypt' DNS challenge to have these signed to certificates, again stored in the zones. Of course, certificates expiring soon will be updated by dns-letsencrypt-secondary. This unikernel does not need any persistent storage, as it leaves this to the dns-primary-git.
We’ve been developing these DNS projects since 2017, and they serve a multitude of functions in the Robur ecosystem. Our domains (like robur.coop) use our DNS server as an authoritative server, and we also use a caching resolver for our biannual MirageOS retreats in Marrakech. Additionally, any MirageOS unikernel can use our client to resolve domain names - using the dns-client devices, or happy-eyeballs, so it’s also beneficial to the OCaml community at large. Robur uses expressive OCaml types (GADT), so we can ensure a given query has a specific shape, like an address record query results in a set of IPv4 addresses.
Robur's DNS implementation can process extensions like dynamic updates, notifications, zone transfers, and request authentications. It can be installed through opam, as all OCaml tools and libraries. You can find our DNS code’s library and unikernels (dns-primary-git, dns-secondary, dns-letsencrypt, and dns-resolver) on GitHub.
Read further posts on DNS from 2018, DNS and CalDAV from 2019, deploying authoritative DNS servers as unikernels (2019), reproducible builds (2019), albatross (2017), deployment (2021), builder-web (2022), visualizations (2022), and monitoring (2022).
If you are interested in supporting or learning more about Robur’s work, please get in touch with us at robur.coop.
Recently, I posted about how vpnkit, built with MirageOS libraries, powers Docker Desktop. Docker Desktop enables users to build, share and run isolated, containerised applications on either a Mac or Windows environment. With millions of users, it's the most popular developer tool on the planet. Hence, MirageOS networking libraries transparently handle the traffic of millions of containers, simplifying many developers' experience every day.
Docker initially started as an easy-to-use packaging of the Linux kernel's isolation primitives, such as namespaces and cgroups. Docker made it convenient for developers to encapsulate applications inside containers, protecting the rest of the system from potential bugs, moving them more easily between machines, and sharing them with other developers. Unfortunately, one of the challenges of running Docker on macOS or Windows is that these Linux primitives are unavailable. Docker Desktop goes to great lengths to emulate them without modifying the user experience of running containers. It runs a (light) Linux VM to host the Docker daemon with additional "glue" helpers to connect the Docker client, running on the host, to that VM. While the Linux VM can run Linux containers, there is often a problem accessing internal company resources. VPN clients are usually configured to allow only "local" traffic from the host, to prevent the host accidentally routing traffic from the Internet to the internal network, compromising network security. Unfortunately network packets from the Linux VM need to be routed, and so are dropped by default. This would prevent Linux containers from being able to access resources like internal company registries.
Vpnkit bridges that gap and circumvents these issues by reversing the MirageOS network stack. It reads raw ethernet frames coming out of the Linux VM and translates them into macOS or Windows high-level (socket) syscalls: it keeps the connection states for every running Docker container in the Linux VMs and converts all their network traffic transparently into host traffic. This is possible because the MirageOS stack is highly modular, feature-rich and very flexible with full implementations of: an ethernet layer, ethernet switching, a TCP/IP stack, DNS, DHCP, HTTP etc. The following diagram shows how the Mirage components are connected together:
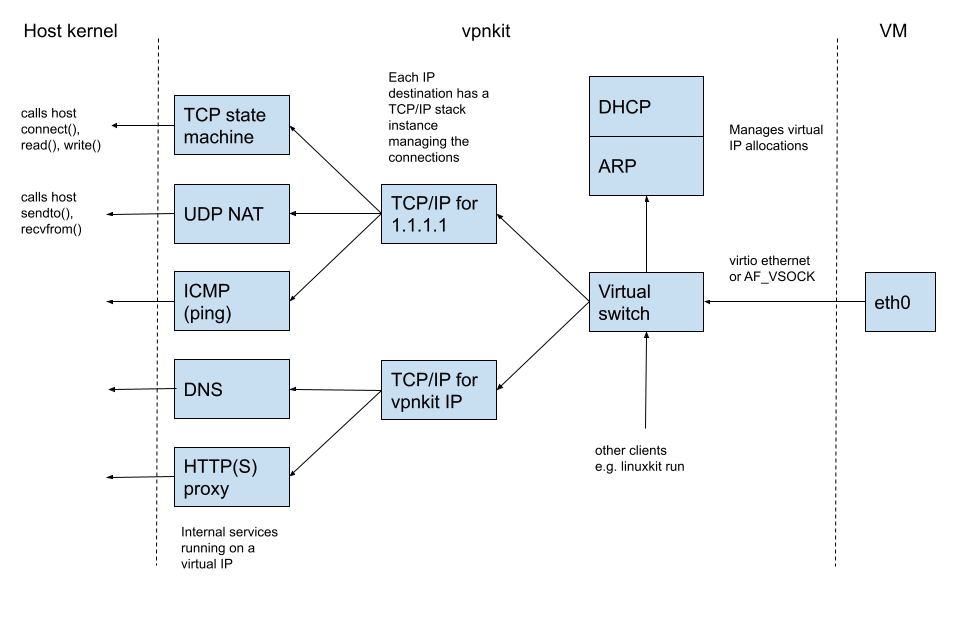
For a more detailed explanation on how vpnkit works with Docker Desktop, read “How Docker Desktop Networking Works Under the Hood.”
My first experience with the Mirage ecosystem was using qubes-mirage-firewall as a way to decrease resource usage for an internal system task. Just before the release of MirageOS 3.9, I participated in testing PVH-mode unikernels with Solo5. I found it interesting with very constructive exchanges and high-quality speakers (@mato, @talex5, @hannesm) to correct some minor bugs.
Observations and an Issue Rises
After the release of Mirage 3.9 and the ability to launch unikernels in PVH-mode with Solo5, my real adventure with Mirage started when I noticed a drop in the bandwidth performance compared to the Linux firewall in Qubes.
The explanation was quickly found: each time a network packet was received, the firewall performed a memory statistic call to decide whether it needed to trigger the garbage collector. The idea behind this was simply to perform the collection steps before running out of memory.
With the previous system (Mini-OS), the amount of free memory was directly accessible; however, with Solo5, the nolibc implementation used the dlmalloc library to manage allocations in the heap. The interface that showed the fraction of occupied memory (mallinfo()) had to loop over the whole heap to count the used and unused areas. This scan is time-linear with the heap size; therefore it took time to make the operation visible when it was performed (in qubes-mirage-firewall) for each packet.
The first proposed solution was to use a less accurate dlmalloc call footprint() which could overestimate the memory usage. This solution had the advantage to be low-cost and increase the bandwitdh performance. However, this overestimation is currently strictly increasing. Without going into details, footprint() gives the amount of memory obtained from the system, which corresponds approximately to the top of the heap. It is possible to give back the top of the heap to Solo5 by calling trim(), which is, sadly, currently not available in the OCaml environment, thus the top of the heap increases. After a while, the amount of free memory falls below a threshold, and our firewall spends its time writing log messages warning about the lack of memory, but it never can solve the problem. The first clue suggested that this was due to a memory leak.
Several Avenues to Explore
As a computer science degree teacher, I can sometimes propose internship topics to students, so I challenged one student to think about this memory leak problem. We tried:
- to understand how to trigger the memory leak problem in a consistent way. Unfortunately it was an erratic behavior which made the analysis of the situation complex.
- to replace
dlmallocby a simpler allocator written from scratch from binary buddy in Knut's TAOCP. The problem with this attempt was the large allocator overhead, as it takes almost 10MB of data structure to manage 32MB of memory. - to keep
dlmallocand count the allocations, releases, reallocations, etc., the hard way with requests to keep the total amount of memory allocated for the unikernel in a simple C variable, like what existed in Mini-OS.
This latest solution looks promising at the beginning of this year, and we're now able to have an estimate of the occupied memory, which goes up and down with the allocations and the garbage collector calls (link). Bravo Julien! It still remains to test and produce the PR to finally close this Issue.
Sharing Files as a Side Project
In parallel to this first experience with MirageOS, and for which I had not practiced OCaml at all, I began developing with MirageOS by writing a tool for my personal usage!
Before telling you about it, I have to add some context: it's easy to have one or more encrypted partitions mountable on the fly with autofs, but I haven't managed to have an encrypted folder that can behave as such an encrypted partition.
In January 2021, the Mirage ecosystem got a library that permits unikernels to communicate using the SSH protocol : Awá-ssh. The server part hadn't been updated since the first version, so I was able to start soaking up by updating this part.
As a developer, I use SSHFS very regularly to mount a remote folder from a server to access and drop—in short, to manipulate files. The good thing is that with my need to have an encrypted folder and the ability to respond in a unikernel to an incoming SSH connection, I was able to capitalize on this work on Awá-ssh server to add the management of an SSHFS mount.
The first work was to follow the SSHFS RFC to handle the SSHFS protocol. Thanks again @hannesm for the help on adapting the awá-unix code to have an awá-mirage module!
Quickly I needed a real file system for my tests. With luck, Mirage offers a file system! Certainly basic, but sufficient for my tests, the venerable FAT16!
With this file system onboard, I was able to complete writing the unikernel, and now I'm able to easily share files (small files, as the FAT16 system doesn't help here) on my local network, thanks to the UNIX version of the unikernel. The great thing about MirageOS is that I'm also able to do it by running the unikernel as a virtual machine without changing the code, just by changing the target at compile time!
However, I still have a lots of work to do to reach my initial goal of being able to build an encrypted folder on Linux (a side project will probably always take long to complete), I need to: - add an encryption library for a disk block - add a real file system with the features of a modern system like btrfs
To answer the first point, and as the abstraction is a strong feature of MirageOS, it is very feasible to change the physical access to the file system in a transparent way. Concerning the second point there are already potential candidates to look at!
MirageOS 4
With the recent release of MirageOS 4, I truly appreciate the new build system that allows fast code iterations through all used dependencies. It considerably helped me fix a runtime issue on Xen and post a PR! Thanks to the whole team for their hard work, and it was a really nice hacking experience! The friendliness and helpfulness of the community is really a plus for this project, so I can't encourage people enough to try writing unikernels for their own needs. You'll get full help and advice from this vibrant community!
The security of communications poses a seemingly never-ending challenge across Cyberspace. From sorting through mountains of spam to protecting our private messages from malicious hackers, cybersecurity has never been more important than it is today. It takes considerable technical skills and dependable infrastructure to run an email service, and sadly, most companies with the ability to handle the billions of emails sent daily make money off mining your sensitive data.
Five years ago, we started to explore an incredible endeavour on how to securely send and receive email. It was my final year in an internship at Cambridge, and the goal was to develop an OCaml library that could parse and craft emails. Thus, Mr. MIME was born. I even gave a presentation on it at ICFP 2016 and introduced Mr. MIME in a previous post. Mr. MIME was also selected by the [NGI DAPSI initiative]((https://tarides.com/blog/2022-03-08-secure-virtual-messages-in-a-bottle-with-scop) last year.
I'm thrilled to shine a spotlight on Mr. MIME as part of the MirageOS 4 release! It was essential to create several small libraries when building and testing Mr. MIME. I've included some samples of how to use Mr. MIME to parse and serialise emails in OCaml, as well as receiving and sending SMTP messages. I then explain how to use all of this via CLI tools. Since unikernels were the foundation on which I built Mr. MIME, the final section explains how to deploy unikernels to handle email traffic.
A Tour of the Many Email Libraries
The following libraries were created to support Mr. MIME:
-
pecuas thequoted-printableserialiser/deserialiser. First, if we strictly consider standards, email transmission can use a 7-bit channel, so we made different encodings in order to safely transmit 8-bit contents via such channels.quoted-printableis one of them, where any non-ASCII characters are encoded.Another encoding is the famous UTF-7 (the one from RFC2152, not the one from RFC2060.5.1.3), which is available in the
yusciilibrary. Please note, Yukoslavian engineers createdYUSCIIencoding to replace the imperial ASCII one. -
rosettais a little library that normalises some inputs such asKOI8-{U,R}orISO-8859-*to Unicode. This ability permitsmrmimeto produce only UTF-8 results that remove the encoding problem. Then, as according to RFC6532 and the Postel law, Mr. MIME can produce only UTF-8 emails. -
keis a small library that implements a ring buffer withbigarray. This library has only one purpose: to restrict a transmission's memory consumption via a ring buffer, like the famous Xen's shared-memory ring buffer. -
emilemay be the most useful library for many users. It parses and re-encodes an email address according to standards. Email addresses are hard! Many details exist, and some of them have meaning while others don't.emileproposes the most standardised way to parse email addresses, and it has the smaller dependencies cone, so it could be used by any project, regardless of size. -
unstrctrdmay be the most obscure library, but it's the essential piece of Mr. MIME. From archeological research into multiple standards, which describe emails along that time, we discovered the most generic form of any values available in your header: the unstructured form. At least email addresses, Date (RFC822), or DKIM-Signature follow this form. More generally, a form such as this can be found in the Debian package description (the RFC822 form).unstrctrdimplements a decoder for it. -
prettymis the last developed library in this context. It's like theFormatmodule withke, and it produces a continuation, which fills a fixed-length buffer.prettymdescribes how to encode emails while complying with the 80-columns rule, so any emails generated by Mr. MIME fit into a catodic monitor! More importantly, with the 7-bit limitation, this rule comes from the MTU limitation of routers, and it's required from the standard point-of-view.
From all of these, we developed mrmime, a library that can transform your email into an OCaml value and create an email from it. This work is related to necessary pieces in multiple contexts, especially the multipart format. We decided to extract a relevant piece of software and make a new library more specialised for the HTTP (which shares many things from emails), then integrate it into Dream. For example see multipart_form.
A huge amount of work has been done on mrmime to ensure a kind of isomorphism, such as x = decode(encode(x)). For this goal, we created a fuzzer that can generate emails. Next, we tried to encode it and then decode the result. Finally, we compared results and checked if they were semantically equal. This enables us to generate many emails, and Mr. MIME won't alter their values.
We also produced a large corpus of emails (a million) that follows the standards. It's really interesting work because it offers the community a free corpus of emails where implementations can check their reliability through Mr. MIME. For a long time after we released Mr. MIME, users wondered how to confirm that what they decoded is what they wanted. It's easy! Just do as we did! Give a billion emails to Mr. MIME and see for yourself. It never fails to decode them all!
At first, we discovered a problem with this implemenation because we couldn't verify Mr. MIME correctly parsed the emails, but we fixed that through our work on hamlet.
hamlet proposes a large corpus of emails, which proves the reliability of Mr. MIME, and mrmime can parse any of these emails. They can be re-encoded, and mrmime doesn't alter anything at any step. We ensure correspondance between the parser and the encoder, and we can finally say that mrmime gives us the expected result after parsing an email.
Parsing and Serialising Emails with Mr. MIME
It's pretty easy to manipulate and craft an email with Mr. MIME, and from our work (especially on hamlet), we are convinced it's reliabile. Here are some examples of Mr. MIME in OCaml to show you how to create an email and how to introspect & analyse an email:
open Mrmime
let romain_calascibetta =
let open Mailbox in
Local.[ w "romain"; w "calascibetta" ] @ Domain.(domain, [ a "gmail"; a "com" ])
let tarides =
let open Mailbox in
Local.[ w "contact" ] @ Domain.(domain, [ a "tarides"; a "com" ])
let date = Date.of_ptime ~zone:Date.Zone.GMT (Ptime_clock.now ())
let content_type =
Content_type.(make `Text (Subtype.v `Text "plain") Parameters.empty)
let subject =
let open Unstructured.Craft in
compile [ v "A"; sp 1; v "simple"; sp 1; v "email" ]
let header =
let open Header in
empty
|> add Field_name.date Field.(Date, date)
|> add Field_name.subject Field.(Unstructured, subject)
|> add Field_name.from Field.(Mailboxes, [ romain_calascibetta ])
|> add (Field_name.v "To") Field.(Addresses, Address.[ mailbox tarides ])
|> add Field_name.content_encoding Field.(Encoding, `Quoted_printable)
let stream_of_stdin () = match input_line stdin with
| line -> Some (line, 0, String.length line)
| exception _ -> None
let v =
let part = Mt.part ~header stream_of_stdin in
Mt.make Header.empty Mt.simple part
let () =
let stream = Mt.to_stream v in
let rec go () = match stream () with
| Some (str, off, len) ->
output_substring stdout str off len ;
go ()
| None -> () in
go ()
(* $ ocamlfind opt -linkpkg -package mrmime,ptime.clock.os in.ml -o in.exe
$ echo "Hello World\\!" | ./in.exe > mail.eml
*)
In the example above, we wanted to create a simple email with an incoming body using the standard input. It shows that mrmime is able to encode the body correctly according to the given header. For instance, we used the quoted-printable encoding (implemented by pecu).
Then, in the example below from the standard input, we wanted to extract the incoming email's header and extract the email addresses (from the From, To, Cc, Bcc and Sender fields). Then, we show them:
open Mrmime
let ps =
let open Field_name in
Map.empty
|> Map.add from Field.(Witness Mailboxes)
|> Map.add (v "To") Field.(Witness Addresses)
|> Map.add cc Field.(Witness Addresses)
|> Map.add bcc Field.(Witness Addresses)
|> Map.add sender Field.(Witness Mailbox)
let parse ic =
let decoder = Hd.decoder ps in
let rec go (addresses : Emile.mailbox list) =
match Hd.decode decoder with
| `Malformed err -> failwith err
| `Field field ->
( match Location.prj field with
| Field (_, Mailboxes, vs) ->
go (vs @ addresses)
| Field (_, Mailbox, v) ->
go (v :: addresses)
| Field (_, Addresses, vs) ->
let vs =
let f = function
| `Group { Emile.mailboxes; _ } ->
mailboxes
| `Mailbox m -> [ m ] in
List.(concat (map f vs)) in
go (vs @ addresses)
| _ -> go addresses )
| `End _ -> addresses
| `Await -> match input_line ic with
| "" -> go addresses
| line
when String.length line >= 1
&& line.[String.length line - 1] = '\\r' ->
Hd.src decoder (line ^ "\\n") 0
(String.length line + 1) ;
go addresses
| line ->
Hd.src decoder (line ^ "\\r\\n") 0
(String.length line + 2) ;
go addresses
| exception _ ->
Hd.src decoder "" 0 0 ;
go addresses in
go []
let () =
let vs = parse stdin in
List.iter (Format.printf "%a\\n%!" Emile.pp_mailbox) vs
(* $ ocamlfind opt -linkpkg -package mrmime out.ml -o out.exe
$ echo "Hello World\\!" | ./in.exe | ./out.exe
romain.calascibetta@gmail.com
contact@tarides.com
*)
From this library, we're able to process emails correctly and verify some meta-information, or we can include some meta-data, such as the Received: field for example.
Sending Emails with SMTP
Of course, when we talk about email, we must talk about SMTP (described by RFC5321). This protocol is an old one (see RFC821 - 1982), and it comes with many things such as:
- 8BITMIME support (1993)
- PLAIN authentication (1999)
- STARTTLS (2002)
- or TLS to submit an email (2018)
- and some others (such as pipeline or enhancement of status code)
Throughout this protocol's history, we tried to pay attention to CVEs like:
- The TURN command (see CVE-1999-0512)
- Authentication into a non-securise channel (see CVE-2017-15042)
- And many others due to buffer overflow
A reimplementation of the SMTP protocol becomes an archeological job where we must be aware of its story via the evolution of its standards, usages, and experimentations; so we tried to find the best way to implement the protocol.
We decided to implement a simple framework in order to describe the state machine of an SMTP server that can upgrade its flow to TLS, so we created colombe as a simple library to implement the foundations of the protocol. In the spirit of MirageOS projects, colombe doesn't depend on lwt, async, or any specific TCP/IP stack, so we ensure the ability to handle incoming/outcoming flow during the process, especially when we want to test/mock our state machine.
With such a design, it becomes easy to integrate a TLS stack. We decided to provide (by default) the SMTP protocol with the STARTTLS command via the great ocaml-tls project. Of course, the end user can choose something else if they want.
From all the above, we recently implemented sendmail (and it's derivation with STARTTLS), which is currently used by some projects such as letters and Sihl or Dream, to send an email to some existing services (see Mailgun or Sendgrid). Thanks to these outsiders for using our work!
Manipulate Emails with CLI tools
mrmime is the bedrock of our email stack. With mrmime, it's possible to manipulate emails as the user wants, so we developed several tools to help the user manipulate emails:
ocaml-dkimprovides a tool to verify and sign an email. This tool is interesting because we put a lot of effort into ensuring that the verification is really memory-bound. Indeed, many tools that verify the DKIM signature do two passes: one to extract the signature and the second to verify. However, it's possible to combine these two steps into one and ensure that such verification can be "piped" into a larger process (such as an SMTP reception server).uspfprovides a verification tool for meta-information (such as the IP address of the sender), like the email's source, and ensure that the email didn't come from an untrusted source. Likeocaml-dkim, it's a simple tool that can be "piped" into a larger process.ocaml-maildiris a MirageOS project that manipulates amaildir"store." Similar to MirageOS,ocaml-maildirprovides a multitude of backends, depending on your context. Of course, the default backend is Unix, but we planned to useocaml-maildirwith Irmin.ocaml-dmarcis finally the tool which aggregates SPF and DKIM meta-information to verify an incoming email (if it comes from an expected authority and wasn't altered).spamtacusis a tool which analyses the incoming email to determine if it's spam or not. It filters incoming emails and rejects spam.conanis an experimental tool that re-implements the commandfileto recognise the MIME type of a given file. Its status is still experimental, but outcomes are promising! We hope to continue the development of it to improve the whole MirageOS stack.blazeis the end-user tool. It aggregates many small programs in the Unix spirit. Every tool can be used with "pipe" (|) and allows the user to do something more complex in its emails. It permits an introspection of our emails in order to aggregate some information, and it proposes a "functional" way to craft and send an email, as you can see below:
$ blaze.make --from din@osau.re \\
| blaze.make wrap --mixed \\
| blaze.make put --type image/png --encoding base64 image.png \\
| blaze.submit --sender din@osau.re --password ****** osau.re
Currently, our development mainly follows the same pattern:
- Make a library that manipulate emails
- Provide a simple tool that does the job implemented by our library
- Integrate it into our "stack" with MirageOS
blaze is a part of this workflow where you can find:
blaze.dkimwhich usesocaml-dkimblaze.spfwhich usesuspfblaze.mdirwhich usesocaml-maildir- and many small libraries such as:
blaze.recvto produce a graph of the route of our emailblaze.send/blaze.submitto send an email to a recipient/an authorityblaze.srvwhich launches a simple SMTP server to receive on emailblaze.descrwhich describes the structure of your email- and some others...
It's interesting to split and prioritise goals of all email possibilities instead of making a monolithic tool which supports far too wide a range of features, although that could also be useful. We ensure a healthy separation between all functionalities and make the user responsible through a self-learning experience, because the most useful black-box does not really help.
Deploying Email Services as Unikernels
As previously mentioned, we developed all of these libraries in the spirit of MirageOS. This mainly means that they should work everywhere, given that we gave great attention to dependencies and abstractions. The goal is to provide a full SMTP stack that's able to send and receive emails.
This work was funded by the NGI DAPSI project, which was jointly funded by the EU's Horizon 2020 research and innovation programme (contract No. 871498) and the Commissioned Research of National Institute of Information.
Such an endeavour takes a huge amount of work on the MirageOS side in order to "scale-up" our infrastructure and deploy many unikernels automatically, so we can propose a coherent final service. We currently use:
albatrossas the daemon which deploys unikernelsocurrentas the Continuous Integration pipeline that compiles unikernels from the source and asksalbatrossto deploy them
We have a self-contained infrastructure. It does not require extra resources, and you can bootstrap a full SMTP service from what we did with required layouts for SPF, DKIM, and DMARC. Our SMTP stack requires a DNS stack already developed and used by mirageos.org. From that, we provide a submit service and a receiver that redirects incoming emails to their real identities.
This graph shows our infrastructure:
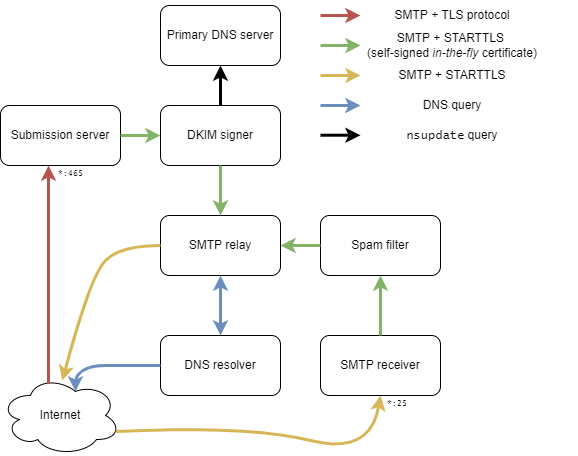
As you can see, we have seven unikernels:
- A simple submission server, from a Git database, that's able to authenticate clients or not
- A DKIM signer that contains your private key that notifies the primary DNS server to record your public key and let receivers verify the integrity of your sent emails
- The primary DNS server that handles your domain name
- The SMTP relay that transfers incoming emails to their right destinations. For instance, for a given user (i.e.,
foo@<my-domain>) from the Git database, the relay knows that the real address isfoo@gmail.com. Thus, it will retransfer the incoming email to the correct SMTP service. - The SMTP relay needs a DNS resolver to get the IP of the destination. This is our fifth unikernel to ensure that we don't use extra resources or control anything necessary to send and receive emails.
- The SMTP receiver does a sanity check on incoming emails, such as SPF and DKIM (DMARC), and prepends the incoming email with results.
- Finally, we have a spam filter that prepends incoming emails with meta information, which helps us to determine if they're spam or not.
An eighth unikernel can help provide a Let's Encrypt certificate under your domain name. This ensures a secure TLS connection from a recognised authority. At the boot of the submission server and the receiver, they ask this unikernel to obtain and use a certificate. Users can now submit emails in a secure way, and senders can transmit their emails in a secure way, too.
The SMTP stack is pretty complex, but any of these unikernels can be used separately from the others. Finally, a full tutorial to deploy this stack from scratch is available here, and the development of unikernels is available in the ptt (Poste, Télégraphe, and Téléphone) repository.
In this blog post, we'll discover build contexts, one of the central changes of MirageOS 4. It's a feature from the Dune build system that enables fully-customizable cross-compilation. We'll showcase its usage by cross-compiling a unikernel to deploy it on an arm64 Linux machine using KVM. This way, a powerful machine does the heavy lifting while a more constrained device such as a Raspberry Pi or a DevTerm deploys it.
We recommend having some familiarity with the MirageOS project in order to fully understand this article. See mirageos.org/docs for more information on that matter.
The unikernel we'll deploy is a caching DNS resolver: https://github.com/mirage/dns-resolver. In a network configuration, the DNS resolver translates domain names to IP adresses, so a personal computer knows which IP should be contacted while accessing mirageos.org. See the first 10 minutes of this YouTube video for a more precise introduction to DNS.
It's common that your ISP provides a default DNS resolver that's automatically set up when connecting to your network (see DHCP), but this may come with privacy issues. The Internet People™ recommend using 1.1.1.1 (Cloudflare) or 8.8.8.8 (Google), but a better solution is to self-host your resolver or use one set up by someone you trust.
The MirageOS 4 Build System
Preliminary Steps
Let's start by setting up MirageOS 4, fetching the project, and configuring it for hvt. hvt is a Solo5-based target that exploits KVM to perform virtualization.
$ opam install "mirage>4" "dune>=3.2.0"
$ git clone https://github.com/mirage/dns-resolver
$ cd dns-resolver
dns-resolver $ mirage configure -t hvt
What is a Configured Unikernel ?
In MirageOS 4, a configured unikernel is obtained by running the mirage configure command in a folder where a config.ml file resides. This file describes the requirements to build the application, usually a unikernel.ml file.
The following hierarchy is obtained. It's quite complex, but today the focus is on the Dune-related part of it:
dns-resolver/
┣ config.ml
┣ unikernel.ml
┃
┣ Makefile
┣ dune <- switch between config and build
┣ dune.config <- configuration build rules
┣ dune.build <- unikernel build rules
┣ dune-project <- dune project definition
┣ dune-workspace <- build contexts definition
┣ mirage/
┃ ┣ context
┃ ┣ key_gen.ml
┃ ┣ main.ml
┃ ┣ <...>-<target>-monorepo.opam
┃ ┗ <...>-<target>-switch.opam
┗ dist/
┗ dune <- rules to produce artifacts
To set up the switch state and fetch dependencies, use the make depends command. Under the hood (see the Makefile), this calls opam and opam-monorepo to gather dependencies. When the command succeeds, a duniverse/ folder is created, which contains the unikernel's runtime dependencies.
$ make depends
While obtaining dependencies, let's start to investigate the Dune-related files.
dune Files
./dune
dune files describe build rules and high-level operations so that the build system can obtain a global dependency graph and know about what's available to build. See dune-files for more information.
In our case, we'll use this file as a switch between two states. This one's first:
(include dune.config)
at the configuration stage (after calling mirage configure).
Then the content is replaced by (include dune.build) if the configuration is successful.
./dune.config
(data_only_dirs duniverse)
(executable
(name config)
(flags (:standard -warn-error -A))
(modules config)
(libraries mirage))
Here, two things are happening. First, the duniverse/ folder is declared as data-only, because we don't want it to interfere with the configuration build, as it should only depend on the global switch state.
Second, a config executable is declared. It contains the second stage of the configuration process, which is executed to generate dune.build, dune-workspace, and various other files required to build the unikernel.
./dune-workspace
The workspace declaration file is a single file at a Dune project's root and describes global settings for the project. See the documentation.
First, it declares the Dune language used and the compilation profile, which is release.
(lang dune 2.0)
(profile release)
For cross-compilation to work, two contexts are declared.
The host context simply imports the configuration from the Opam switch:
(context (default))
We use the target context in a more flexible way, and there are many fields allowing users to customize settings such as:
- OCaml compilation and linking flags
- C compilation and linking flags
- Dynamic linking
- OCaml compiler toolchain: any compiler toolchain described by a
findlib.conffile in the switch can be used by Dune in a build context. See https://linux.die.net/man/5/findlib.conf for more details on how to write such a file. An important fact about the compiler toolchain is that Dune derives the C compilation rules from the configuration, as described inocamlc -config.
(context (default
(name solo5) ; name of the context
(host default) ; inform dune that this is cross-compilation
(toolchain solo5) ; use the ocaml-solo5 compiler toolchain
(merlin) ; enable merlin for this context
(disable_dynamically_linked_foreign_archives true)
))
./dune.build
When configuration is done, this file is included by ./dune.
- The generated source code is imported along with the unikernel sources:
(copy_files ./mirage/*)
- An executable is declared within the cross-compilation build context, using the statically-known list of dependencies:
(executable
(enabled_if (= %{context_name} "solo5"))
(name main)
(modes (native exe))
(libraries arp.mirage dns dns-mirage dns-resolver.mirage dns-server
ethernet logs lwt mirage-bootvar-solo5 mirage-clock-solo5
mirage-crypto-rng-mirage mirage-logs mirage-net-solo5 mirage-random
mirage-runtime mirage-solo5 mirage-time tcpip.icmpv4 tcpip.ipv4
tcpip.ipv6 tcpip.stack-direct tcpip.tcp tcpip.udp)
(link_flags :standard -w -70 -color always -cclib "-z solo5-abi=hvt")
(modules (:standard \\ config manifest))
(foreign_stubs (language c) (names manifest))
)
- Solo5 requires the usage of a small chunk of C code derived from a manifest file, which is also generated:
(rule
(targets manifest.c)
(deps manifest.json)
(action
(run solo5-elftool gen-manifest manifest.json manifest.c)))
- The obtained image is renamed, and the default alias is overriden so that
dune buildworks as expected:
(rule
(target resolver.hvt)
(enabled_if (= %{context_name} "solo5"))
(deps main.exe)
(action
(copy main.exe %{target})))
(alias
(name default)
(enabled_if (= %{context_name} "solo5"))
(deps (alias_rec all)))
./dist/dune
Once the unikernel is built, this rule describes how it's promoted back into the source tree that resides inside the dist/ folder.
(rule
(mode (promote (until-clean)))
(target resolver.hvt)
(enabled_if (= %{context_name} "solo5"))
(action
(copy ../resolver.hvt %{target})))
Cross-Compiling to x86_64/hvt
If everything went correctly, the unikernel source tree should be populated with all the build rules and dependencies needed. It's just a matter of
$ make build
or
$ mirage build
or
$ dune build --root .
Finally, we obtain an hvt-enabled executable in the dist/ folder. To execute it, the we must first:
- install the HVT tender:
solo5-hvtthat is installed in thesolo5package. - prepare a TAP interface for networking: note that it requires access to the Internet to be able to query the root DNS servers.
That executable can run using solo5-hvt --net:service=<TAP_INTERFACE> dist/resolver.hvt --ipv4=<UNIKERNEL_IP> --ipv4-gateway=<HOST_IP>.
Cross-Compiling to ARM64/HVT
When cross-compiling to ARM64, the scheme looks like this:
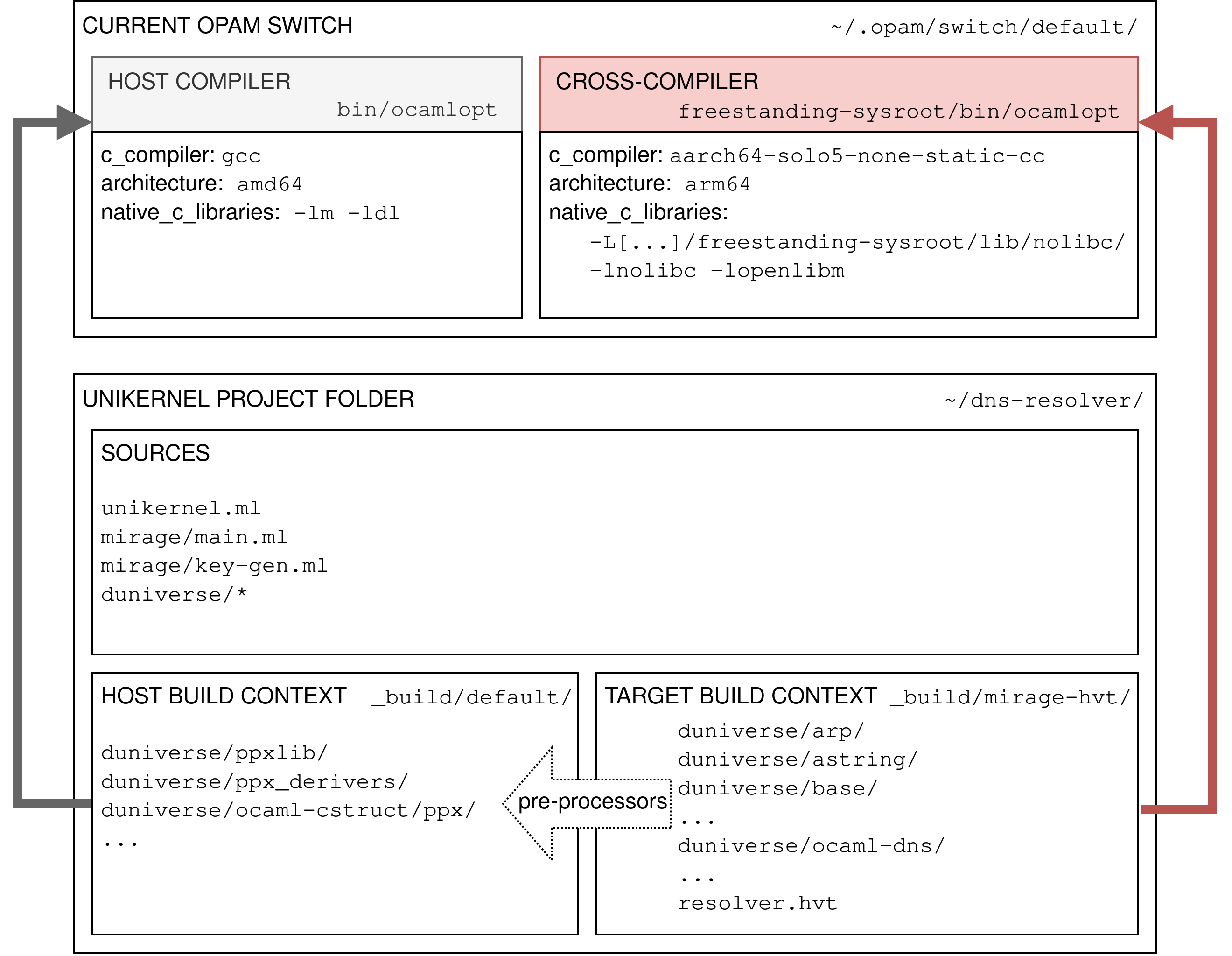
So, from the Mirage build system viewpoint, nothing changes. The only part that changes is the compiler used. We switch from a host-architecture ocaml-solo5 to a cross-architecture version of ocaml-solo5.
To achieve that, we must pin a version of ocaml-solo5 configured for cross-compilation and pin the cross-compiled Solo5 distribution:
$ opam pin solo5-cross-aarch64 https://github.com/Solo5/solo5.git#v0.7.1
$ opam pin ocaml-solo5-cross-aarch64 https://github.com/mirage/ocaml-solo5.git#v0.8.0
Note that doing this will uninstall ocaml-solo5. Indeed, they both define the same toolchain name solo5.
KVM is now enabled by default in most Raspberry Pi kernel distributions, but for historical interest, this blog post shows how to enable KVM and cross-compile the Linux kernel: https://mirageos.org/docs/arm64
Then, simply run
$ dune build / mirage build / make
A cross-compiled binary will appear in the dist/ folder:
$ file dist/resolver.hvt
dist/resolver.hvt: ELF 64-bit LSB executable, ARM aarch64, version 1 (SYSV), statically linked, interpreter /nonexistent/solo5/, for OpenBSD, with debug_info, not stripped
On the Raspberry Pi target, simply copy the unikernel binary, install the Solo5 tender (opam install solo5), and run solo5-hvt unikernel.hvt to execute the unikernel.
Compiling to a New Target or Architecture
Case 1: An Already Known Mirage Target (Unix / HVT / etc.)
In that situation, mirage configure -t <target> should already output the correct source code and dependencies for the target. This is notably under the assumption that the involved C code is portable.
The dune-workspace can then be tweaked to reference the wanted cross-compiler distribution. ocaml-solo5 is an example on how a cross-compiler distribution can be set up and installed inside an Opam switch.
Case 2: A New Target
In this situation, a more in-depth comprehension of Mirage is required.
- Set up a cross-compiler distribution: see previous case.
- Implement a base layer:
An OCaml module named
<Target>_osis required to implement the base features of MirageOS, namely job scheduling and timers. Seemirage-solo5. - Implement the target signature in the Mirage tool:
Mirage_target.Snotably describes the packages required and the Dune rules needed to build for that target. - To obtain feature parity with the other Mirage targets and be able to use the existing devices, device drivers should be implemented:
- Networking: see mirage-net-solo5
- Console: see mirage-console-solo5
- Block Device: see mirage-block-solo5
- Clock: see mirage-clock-solo5
Conclusion
This blog post shows how the Mirage tool acts as super glue between the build system, the mirage libraries, the host system, and the application code. One of the major changes with MirageOS 4 is the switch from OCamlbuild to Dune.
Using Dune to build unikernels enables cross-compilation through build contexts that use various toolchains. It also enables the usage of the Merlin tool to provide IDE features when writing the application. Finally, a single-workspace containg all the unikernels' code lets developers investigate and edit code anywhere in the stack, allowing for fast iterations when debugging libraries and improving APIs.
On behalf of the MirageOS team, I am delighted to announce the release of MirageOS 4.0.0!
Since its first release in 2013, MirageOS has made steady progress towards deploying self-managed internet infrastructure. The project’s initial aim was to self-host as many services as possible aimed at empowering internet users to deploy infrastructure securely to own their data and take back control of their privacy. MirageOS can securely deploy static website hosting with “Let’s Encrypt” certificate provisioning and a secure SMTP stack with security extensions. MirageOS can also deploy decentralised communication infrastructure like Matrix, OpenVPN servers, and TLS tunnels to ensure data privacy or DNS(SEC) servers for better authentication.
The protocol ecosystem now contains hundreds of libraries and services millions of daily users. Over these years, major commercial users have joined the projects. They rely on MirageOS libraries to keep their products secure. For instance, the MirageOS networking code powers Docker Desktop’s VPNKit, which serves the traffic of millions of containers daily. Citrix Hypervisor uses MirageOS to interact with Xen, the hypervisor that powers most of today’s public cloud. Nitrokey is developing a new hardware security module based on MirageOS. Robur develops a unikernel orchestration system for fleets of MirageOS unikernels. Tarides uses MirageOS to improve the Tezos blockchain, and Hyper uses MirageOS to build sensor analytics and an automation platform for sustainable agriculture.
In the coming weeks, our blog will feature in-depth technical content for the new features that MirageOS brings and a tour of the existing community and commercial users of MirageOS. Please reach out If you’d like to tell us about your story.
Install MirageOS 4
The easiest way to install MirageOS 4 is by using the opam package manager version 2.1. Follow the installation guide for more details.
$ opam update
$ opam install 'mirage>4'
Note: if you upgrade from MirageOS 3, you will need to manually clean
the previously generated files (or call mirage clean before
upgrading). You would also want to read the complete list of API
changes. You can see
unikernel examples in
mirage/mirage-skeleton,
robur-coop/unikernels or
tarides/unikernels.
About MirageOS
MirageOS is a library operating system that constructs unikernels for secure, high-performance, low-energy footprint applications across various hypervisor and embedded platforms. It is available as an open-source project created and maintained by the MirageOS Core Team. A unikernel can be customised based on the target architecture by picking the relevant MirageOS libraries and compiling them into a standalone operating system, strictly containing the functionality necessary for the target. This minimises the unikernel’s footprint, increasing the security of the deployed operating system.
The MirageOS architecture can be divided into operating system libraries, typed signatures, and a metaprogramming compiler. The operating system libraries implement various functionalities, ranging from low-level network card drivers to full reimplementations of the TLS protocol, as well as the Git protocol to store versioned data. A set of typed signatures ensures that the OS libraries are consistent and work well in conjunction with each other. Most importantly, MirageOS is also a metaprogramming compiler that can input OCaml source code along with its dependencies, and a deployment target description to generate an executable unikernel, i.e., a specialised binary artefact containing only the code needed to run on the target platform. Overall, MirageOS focuses on providing a small, well-defined, typed interface with the system components of the target architecture.
What’s New in MirageOS 4?
The MirageOS4 release focuses on better integration with existing ecosystems. For instance, parts of MirageOS are now merged into the OCaml ecosystem, making it easier to deploy OCaml applications into a unikernel. Plus, we improved the cross-compilation support, added more compilation targets to MirageOS (for instance, we have an experimental bare-metal Raspberry-Pi 4 target, and made it easier to integrate MirageOS with C and Rust libraries.
This release introduces a significant change in how MirageOS compiles
projects. We developed a new tool called
opam-monorepo that
separates package management from building the resulting source
code. It creates a lock file for the project’s dependencies, downloads
and extracts the dependency sources locally, and sets up a dune
workspace,
enabling dune build to build everything simultaneously. The MirageOS
4.0 release also contains improvements in the mirage CLI tool, a new
libc-free OCaml runtime (thus bumping the minimal required version of
OCaml to 4.12.1), and a cross-compiler for OCaml. Finally, MirageOS
4.0 now supports the use of familiar IDE tools while developing
unikernels via Merlin, making day-to-day coding much faster.
Review a complete list of features on the MirageOS 4 release page. And check out the breaking API changes.
About Cross-Compilation and opam overlays
This new release of MirageOS adds systematic support for cross-compilation to all supported unikernel targets. This means that libraries that use C stubs (like Base, for example) can now seamlessly have those stubs cross-compiled to the desired target. Previous releases of MirageOS required specific support to accomplish this by adding the stubs to a central package. MirageOS 4.0 implements cross-compilation using Dune workspaces, which can take a whole collection of OCaml code (including all transitive dependencies) and compile it with a given set of C and OCaml compiler flags.
The change in how MirageOS compiles projects that accompanies this release required implementing a new developer experience for Opam users, to simplify cross-compilation of large OCaml projects.
A new tool called opam-monorepo separates package management from building the resulting source code. It is an opam plugin that:
- creates a lock file for the project’s dependencies
- downloads and extracts the dependency sources locally
- sets up a Dune workspace so that
dune buildbuilds everything in one go.
opam-monorepo is already available in opam and can be used
on many projects which use Dune as a build system. However, as we
don’t expect the complete set of OCaml dependencies to use Dune, we
MirageOS maintainers are committed to maintaining patches that build
the most common dependencies with dune. These packages are hosted in two
separate Opam repositories:
- dune-universe/opam-overlays
adds patched packages (with a
+duneversion) that compile with Dune. - dune-universe/mirage-opam-overlays
add patched packages (with a
+dune+mirageversion) that fix cross-compilation with Dune.
When using the mirage CLI tool, these repositories are enabled by default.
In Memory of Lars Kurth

We dedicate this release of MirageOS 4.0 to Lars Kurth. Unfortunately, he passed away early in 2020, leaving a big hole in our community. Lars was instrumental in bringing the Xen Project to fruition, and we wouldn’t be here without him.