Introducing Irmin: Git-like distributed, branchable storage
By Thomas Gazagnaire - 2014-07-18
This is the first post in a series which will describe Irmin, the new Git-like storage layer for Mirage OS 2.0. This post gives a high-level description on Irmin and its overall architecture, and later posts will detail how to use Irmin in real systems.
Irmin is a library to persist and synchronize distributed data structures both on-disk and in-memory. It enables a style of programming very similar to the Git workflow, where distributed nodes fork, fetch, merge and push data between each other. The general idea is that you want every active node to get a local (partial) copy of a global database and always be very explicit about how and when data is shared and migrated.
Irmin is not, strictly speaking, a full database engine. It is, as are all other components of Mirage OS, a collection of libraries designed to solve different flavours of the challenges raised by the CAP theorem. Each application can select the right combination of libraries to solve its particular distributed problem. More precisely, Irmin consists of a core of well-defined low-level data structures that specify how data should be persisted and be shared across nodes. It defines algorithms for efficient synchronization of those distributed low-level constructs. It also builds a collection of higher-level data structures, like persistent mergeable queues, that can be used by developers without having to know precisely how Irmin works underneath.
Since it's a part of Mirage OS, Irmin does not make strong assumptions about the OS environment that it runs in. This makes the system very portable, and the details below hold for in-memory databases as well as for slower persistent serialization such as SSDs, hard drives, web browser local storage, or even the Git file format.
Persistent Data Structures
Persistent data structures are well known and used pervasively in many different areas. The programming language community has investigated the concepts widely (and this is not limited to functional programming), and in the meantime, the systems community experimented with various persistent strategies such as copy-on-write filesystems. In most of these systems, the main concern is how to optimize the space complexity by maximizing the sharing of immutable sub-structures.
The Irmin design ideas share roots with previous works on persistent data structures, as it provides an efficient way to fork data structures, but it also explores new strategies and mechanisms to be able to efficiently merge back these forked structures. This offers programming constructs very similar to the Git workflow.
Irmin focuses on two main aspects:
-
Semantics: what properties the resulting merged objects should verify.
-
Complexity: how to design efficient merge and synchronization primitives, taking advantage of the immutable nature of the underlying objects.
Although it is pervasively used, data persistence has a very broad and fuzzy meaning. In this blog post, I will refer to data persistence as a way for:
-
a single process to lazily populate a process memory on startup. You need this when you want the process to be able to resume while holding part of its previous state if it crashes
-
concurrent processes to share references between objects living in a global pool of data. Sharing references, as opposed to sharing values, reduces memory copies and allow different processes to concurrently update a shared store.
In both cases, you need a global pool of data (the Irmin block store) and a way to name values in that pool (the Irmin tag store).
The Block Store: a Virtual Heap
Even high-level data structures need to be allocated in memory, and it is the purpose of the runtime to map such high-level constructs into low-level memory graph blocks. One of the strengths of OCaml is the very simple and deterministic mapping from high-level data structures to low-level block representations (the heap): see for instance, the excellent series of blog posts on OCaml internals by Richard W. Jones, or Chapter 20: Memory Representation of Values in Real World OCaml.
An Irmin block store can be seen as a virtual OCaml heap that uses a more abstract way of connecting heap blocks. Instead of using the concrete physical memory addresses of blocks, Irmin uses the hash of the block contents as an address. As for any content-addressable storage, this gives Irmin block stores a lot of nice properties and greatly simplifies the way distributed stores can be synchronized.
Persistent data structures are immutable, and once a block is created in the block store, its contents will never change again. Updating an immutable data structure means returning a completely new structure, while trying to share common sub-parts to avoid the cost of making new allocations as much as possible. For instance, modifying a value in a persistent tree means creating a chain of new blocks, from the root of the tree to the modified leaf. For convenience, Irmin only considers acyclic block graphs -- it is difficult in a non-lazy pure language to generate complex cyclic values with reasonable space usage.
Conceptually, an Irmin block store has the following signature:
type t
(** The type for Irmin block store. *)
type key
(** The type for Irmin pointers *)
type value = ...
(** The type for Irmin blocks *)
val read: t -> key -> value option
(** [read t k] is the block stored at the location [k] of the
store. It is [None] if no block is available at that location. *)
val add: t -> key -> value -> t
(** [add t k v] is the *new* store storing the block [v] at the
location [k]. *)
Persistent data structures are very efficient to store in memory and on disk as you do not need write barriers, and updates can be written sequentially instead of requiring random access into the data structure.
The Tag Store: Controlled Mutability and Concurrency
So far, we have only discussed purely functional data structures, where updating a structure means returning a pointer to a new structure in the heap that shares most of its contents with the previous one. This style of programming is appealing when implementing complex protocols as it leads to better compositional properties.
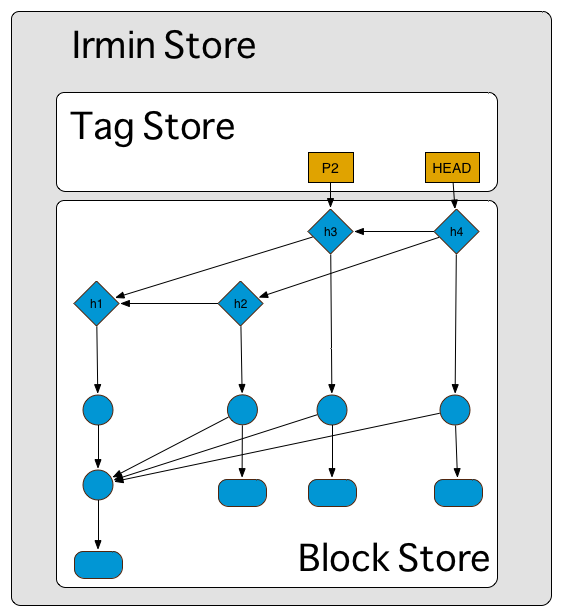
However, this makes sharing information between processes much more difficult, as you need a way to "inject" the state of one structure into another process's memory. In order to do so, Irmin borrows the concept of branches from Git by relating every operation to a branch name, and modifying the tip of the branch if it has side-effects. The Irmin tag store is the only mutable part of the whole system and is responsible for mapping some global (branch) names to blocks in the block store. These tag names can then be used to pass block references between different processes.
A block store and a tag store can be combined to build a higher-level store (the Irmin store) with fine concurrency control and atomicity guarantees. As mutation happens only in the tag store, we can ensure that as long a given tag is not updated, no change made in the block store will be visible by anyone. This also gives a nice story for concurrency: as in Git, creating a concurrent view of the store is the straightforward operation of creating a new tag that denotes a new branch. All concurrent operations can then happen on different branches:
type t
(** The type for Irmin store. *)
type tag
(** Mutable tags *)
type key = ...
(** The type for user-defined keys (for instance a list of strings) *)
type value = ...
(** The type for user-defined values *)
val read: t -> ?branch:tag -> key -> value option
(** [read t ?branch k] reads the contents of the key [k] in the branch
[branch] of the store [t]. If no branch is specified, then use the
["HEAD"] one. *)
val update: t -> ?branch:tag -> key -> value -> unit
(** [update t ?branch k v] *updates* the branch [branch] of the store
[t] the association of the key [key] to the value [value]. *)
Interactions between concurrent processes are completely explicit and
need to happen via synchronization points and merge events (more on
this below). It is also possible to emulate the behaviour of
transactions by recording the sequence of operations (read and
update) on a given branch -- that sequence is used before a merge
to check that all the operations are valid (i.e. that all reads in the
transaction still return the same result on the current tip of the
store) and it can be discarded after the merge takes place.
Merging Data Structures
To merge two data structures in a consistent way, one has to compute the sequence of operations which leads, from an initial common state, to two diverging states (the ones that you want to merge). Once these two sequences of operations have been found, they must be combined (if possible) in a sensible way and then applied again back on the initial state, in order to get the new merged state. This mechanism sounds nice, but in practice it has two major drawbacks:
- It does not specify how we find the initial state from two diverging states -- this is generally not possible (think of diverging counters); and
- It means we need to compute the sequence of
updateoperations that leads from one state to an other. This is easier than finding the common initial state between two branches, but is still generally not very efficient.
In Irmin, we solve these problems using two mechanisms.
First of all, an interesting observation is that that we can model the
sequence of store tips as a purely functional data-structure. We model
the partial order of tips as a directed acyclic graph where nodes are
the tips, and there is an edge between two tips if either (i) one is
the result of applying a sequence of updates to the other, or (ii)
one is the result of a merge operation between the other and some
other tips. Practically speaking, that means that every tip should
contains the list of its predecessors as well as the actual data it
associated to. As it is purely functional, we can (and we do) store
that graph in an Irmin block store.
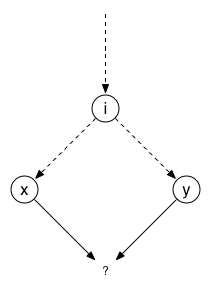
Having a persistent and immutable history is good for various obvious reasons, such as access to a forensics if an error occurs or snapshot and rollback features for free. But another less obvious useful property is that we can now find the greatest common ancestors of two data structures without an expensive global search.
The second mechanism is that we require the data structures used in
Irmin to be equipped with a well-defined 3-way merge operation, which
takes two diverging states, the corresponding initial state (computed
using the previous mechanism) and that return either a new state or a
conflict (similar to the EAGAIN exception that you get when you try
to commit a conflicting transaction in more traditional transactional
databases). Having access to the common ancestors makes a great
difference when designing new merge functions, as usually no
modification is required to the data-structure itself. In contrast,
the conventional approach is more invasive as it requires the data
structure to carry more information about the operation history
(for instance conflict-free replicated
datatypes, which relies on unbounded vector clocks).
We have thus been designing interesting data structure equipped with a 3-way merge, such as counters, queues and ropes.
This is what the implementation of distributed and mergeable counters looks like:
type t = int
(** distributed counters are just normal integers! *)
let merge ~old t1 t2 = old + (t1-old) + (t2-old)
(** Merging counters means:
- computing the increments of the two states [t1] and [t2]
relatively to the initial state [old]; and
- and add these two increments to [old]. *)
Next steps, how to git at your data
From a design perspective, having access to the history makes it easier to design complex data structures with good compositional properties to use in unikernels. Moreover, as we made few assumptions on how the substrate of the low-level constructs need to be implemented, the Irmin engine can be be ported to many exotic backends such as JavaScript or anywhere else that Mirage OS runs: this is just a matter of implementing a rather trivial signature.
From a developer perspective, this means that the full history of operations is
available to inspect, and that the history model is very similar to the Git
workflow that is increasingly familiar. So similar, in fact, that we've
developed a bidirectional mapping between Irmin data structures and the Git
format to permit the git command-line to interact with.
The next post in our series explains what Dave Scott has been doing with the new version of the Xenstore database that powers every Xen host, where the entire database is stored in a prefix-tree Irmin data-structure and exposed as a Git repository which is live-updated! Here's a sneak preview...